Prepare a training dataset for ANNHUB
Data collection
Before data can be used to design a neural network, four steps in data preparation might be applied.
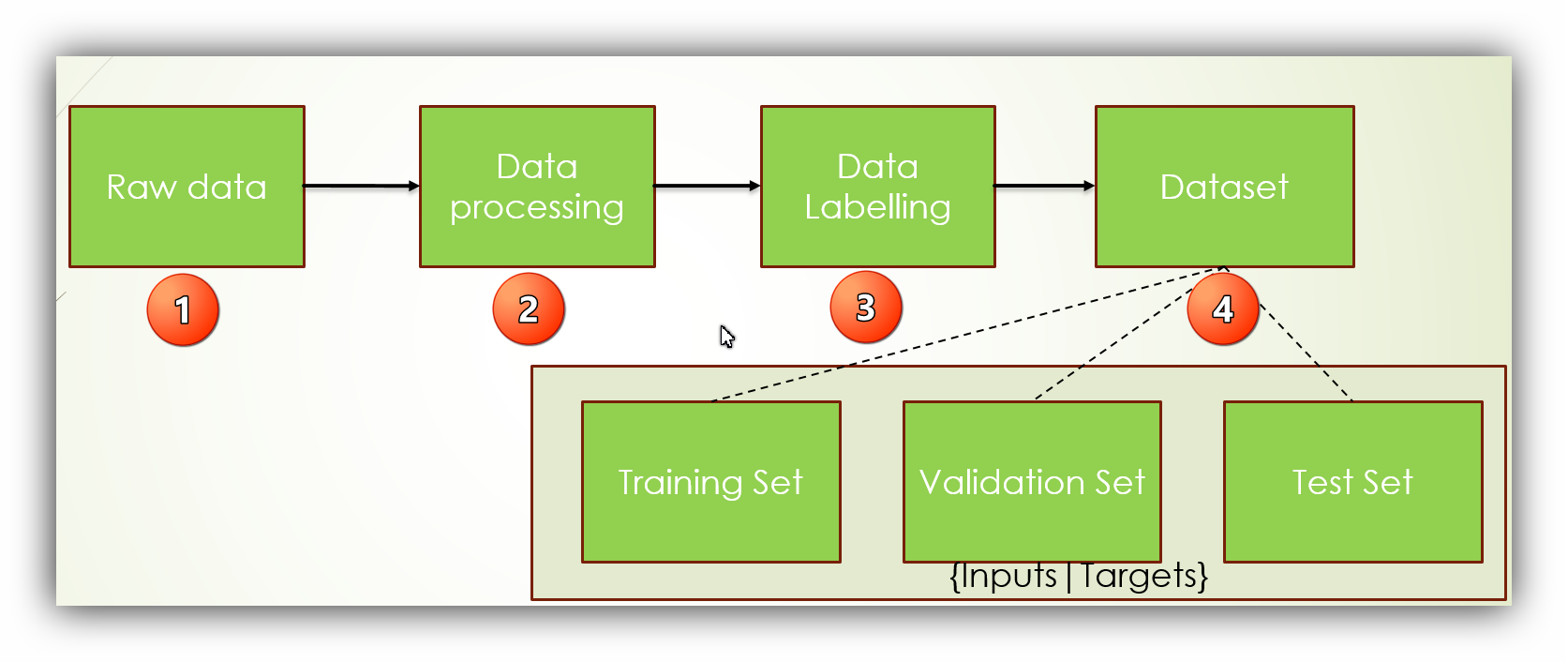
1. Raw data is first collected.
2. In the data processing step, the dataset can be cleaned by removing corrupted and incorrect records. Transformation techniques may be used to achieve useful features or to reduce data dimensions. Categorical variables in the dataset are also converted to numerical values that can be used.
3. Data labelling might be applied to label targets.
4. Dataset is then divided into three sets: Training set is used to train a neural network, a validation set is used to prevent the over-fitting issue, and the test set is used to evaluate how well the trained neural network could cope with completely new data-set
Prepare data for ANNHUB
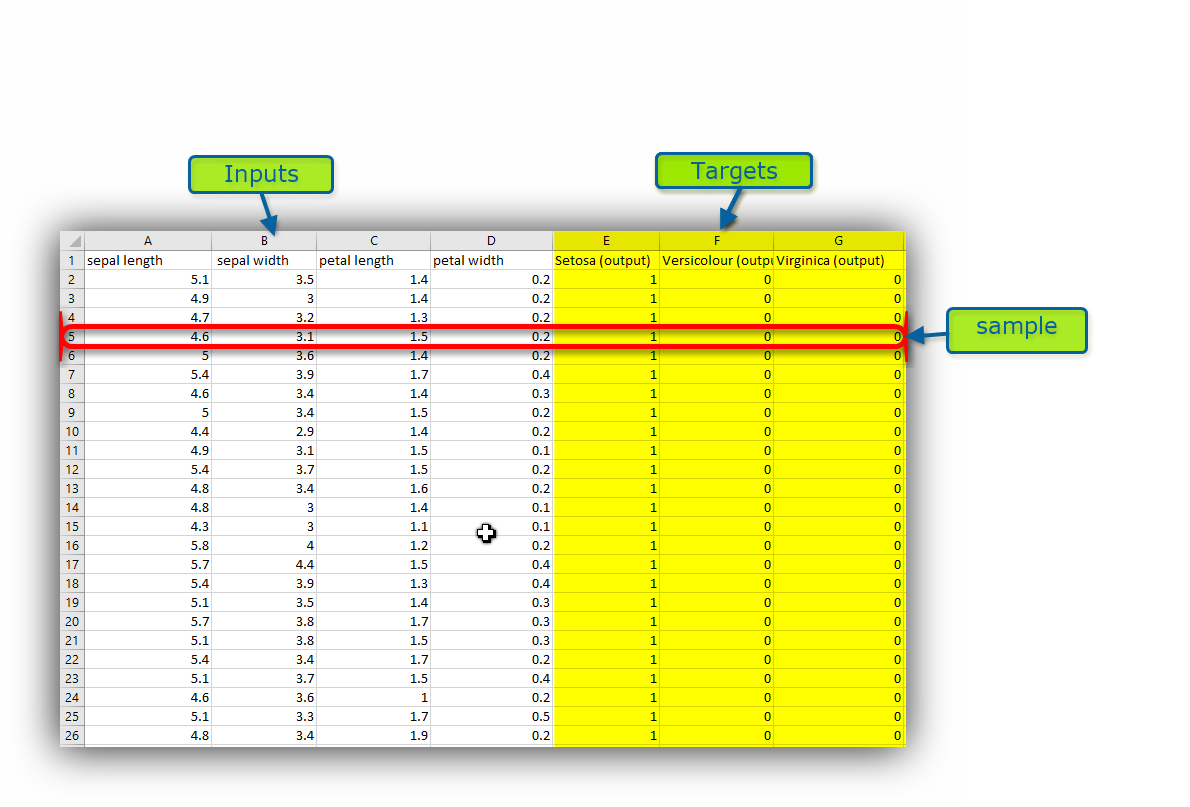
The collected data must be presented in comma-separated values (CSV) format.
The first row contains the header file that includes the inputs and targets' names.
The keywords (output, target, class) must be used to identify targets from inputs' names.
Each row represents a data sample or an observation.
After preparing data, now you're ready for ANNHUB.
Note: You can have as many inputs and outputs as you want.