Understanding neural network design flow
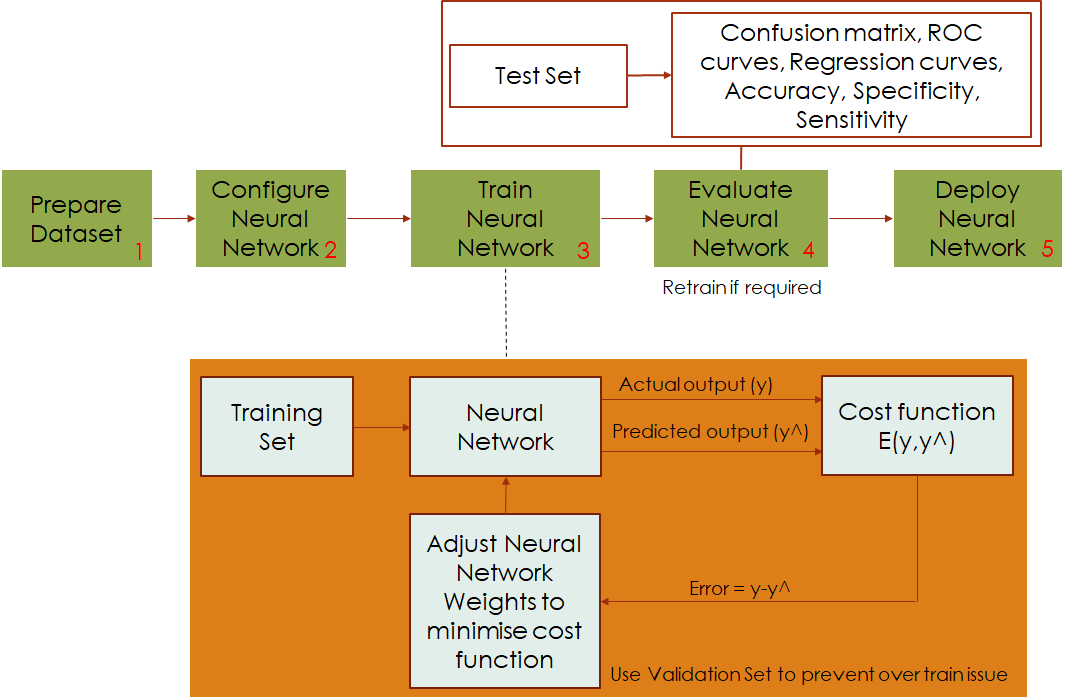
The Neural Network design flow typically contains five major steps, as shown above.
The first step involves data-set preparation. In this step, based on the requirements of an application, raw data is collected, processed and transformed to form a dataset that contains a collection of input-target pairs. The data set is then divided into three small sets, including training set, validation set, and test set. The training set is used to train a Neural Network, the validation set is used to prevent over-fitting issues during the training process, and the test set is used to evaluate the Neural Network stability and test if it could cope with a completely new dataset.
Once the dataset is available, the Neural Network structure will be configured accordingly. This step involves defining how many input nodes, hidden nodes, and output nodes of the Neural Network. The activation functions for hidden layers and output layers are also being described in this step. Both pre-processing and post-processing methods are configured to transform data-set inputs into the correct range that the Neural Network can use and reverse its outputs to the range that match data-set targets. This step also allows users to choose the correct training algorithm and the cost function to be used in a training procedure.
After the Neural Network is configured, a selected training algorithm that uses the training set will teach Neural Network to learn data-set input-target mapping. This training algorithm is based on the optimization process that minimizes the errors by adjusting the Neural Network weights. During that training process, the validation set is used to prevent the over-fitting issue.
The trained Neural Network is then evaluated in step 4 to test how it responds to an entirely new dataset. Evaluation techniques such as confusion matrix, ROC curves, regression curves will be used to decide if the Neural Network must be retrained due to poor generalization.
If the trained Neural Network copes well with a new dataset and its performance meets desired criteria in terms of robustness and accuracy, it will be deployed to a given application in step 5.