List of supported deep learning modules in DLHUB
DLHUB supports many different deep learning modules that help user to create and customize their AI model with simple clicks
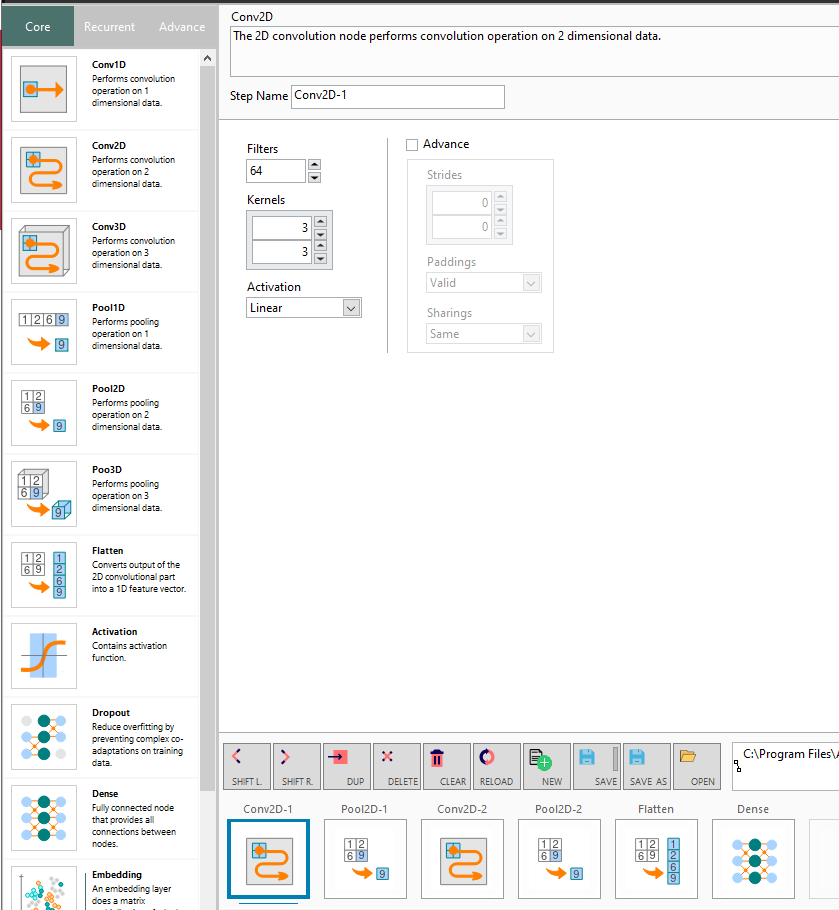
Conv2D

The 2D convolution node performs convolution operation on 2 dimensional data.
Parameters
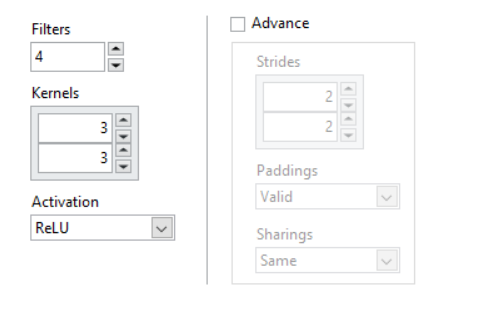
Filters: The number of output filters in the convolution
Kernels: The height and width of the 2D convolution window.
Activation: The activation function
Strides: The strides of the convolution along the height and width.
- Increase Strides to reduce the size of the output volume.
- The default value is (2,2)
- Strides of (2,2) is sometimes used as a replacement to max pooling
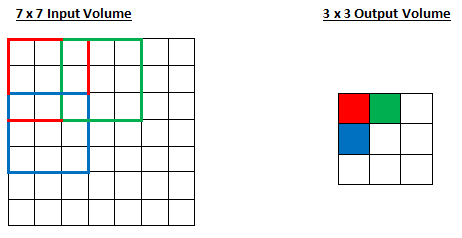
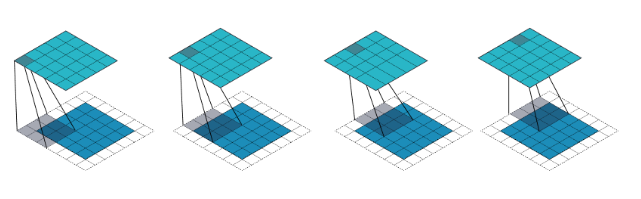
Paddings: Padding is used to preserve the size of the input volume.
For example, when you apply three 5 x 5 x 3 filters to a 32 x 32 x 3 input volume, the output volume would be 28 x 28 x 3. Notice that the spatial dimensions decrease. As we keep applying convolution layers, the size of the volume will drop faster than we would like. In the previous layers of our network, we want to preserve as much information about the original input volume so that we can extract those low-level features. Let’s say we want to apply the same convolution layer, but we want the output volume to remain 32 x 32 x 3. To do this, we can use a zero padding of size 2 to that layer. Zero padding pads the input volume with zeros around the border. If we think about a zero padding of two, then this would result in a 36 x 36 x 3 input volume.
- Valid: the input volume is not zero-padded and the spatial dimensions are allowed to reduce via the natural application of convolution.
- Same: preserve the spatial dimensions of the volume such that the output volume size matches the input volume size. In order to achieve this, there is a one-pixel-width padding around the image, and the filter slides outside the image into this padding area.
Pool 2D
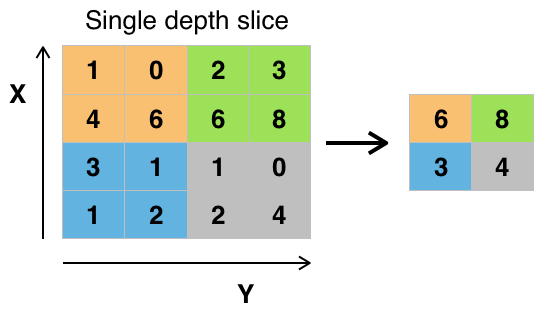
Down-sampling layer that performs max or average pooling operation on 2 dimensional data.
Parameters
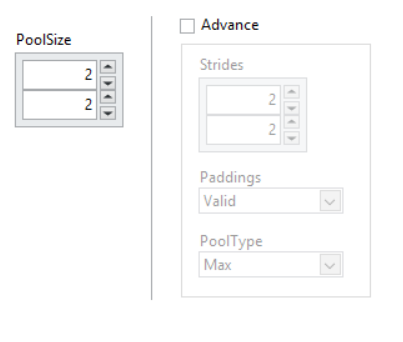
PoolSize: The size of the pooling windows for both dimensions (height and width)
Strides: Stride (x, y) integers specifies the step of the convolution along the x and y axis of the input volume.
- Increase Strides to reduce the size of the output volume.
- The default value is (2,2)
Paddings: Padding is used to preserve the size of the input volume.
- Valid: the input volume is not zero-padded and the spatial dimensions are allowed to reduce via the natural application of convolution.
- Same: preserve the spatial dimensions of the volume such that the output volume size matches the input volume size
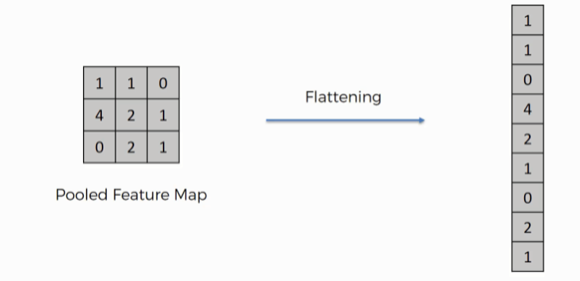
Flatten
Flatten node converts the output of the 2D convolutional part into a 1D feature vector that can be used to have it processed further, such as using a Dense node.
Dense
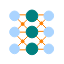
The dense or a fully connected (FC) layer provides all connections between nodes. This module is normally used as hidden or output layers after the Flatten layer
Parameters
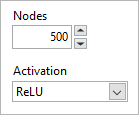
Nodes: Number of nodes in the dense layer. If the dense layer is the output layer (last layer), the number of nodes must be the same as the number of classes specified in the data-set
Activations
Activation

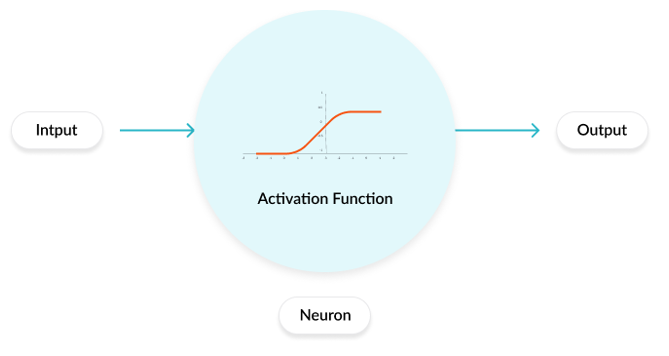
A layer contains only an activation function. Activation functions are mathematical equations that determine the output of a neural network that should be activated (“fired”) or not. Activation functions also help normalize the network outputs to a range between 1 and 0 or between -1 and 1.
Parameters
Dropout
Dropout node helps to reduce the over fitting in neural networks by preventing complex co-adaptations on training data.
This layer “drops out” or ignore a random set of neurons. As a result, any weights related to these neurons will not be updated during the training process. The effect is that the network becomes less sensitive to the specific weights of neurons. This effect results in a network that is capable of better generalization and is less likely to over-fit the training data
Parameters
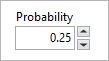
Probability
Defines probability of randomly dropping out the neuron in the layer.
- Default value is 0.25
- A probability too low has minimal effect and a value too high results in under-learning by the network.
Tips:
- You are likely to get better performance when dropout is used on a larger network, giving the model more of an opportunity to learn independent representations.
- Use a large learning rate with decay and a large momentum. Increase your learning rate by a factor of 10 to 100 and use a high momentum value of 0.9 or 0.99.
Transfer Learning

Transfer learning is the process of taking a pre-trained model (the weights and parameters of a network that has been trained on a large dataset by somebody else) and “fine-tuning” the model with a specified dataset. The idea is that the aforementioned pre-trained model will act as a feature extractor. TLModel (Transfer Learning model) node contains pre-trained Neural Network layers except for the last layer (output layer).
Since TLModel does not contain the last output layer, the dense layers usually are used with TLModel to create a complete deep learning model. The weights of the TLModel are locked down during the training.
Parameters
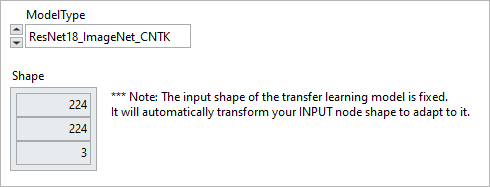
ModelType: is the list of pre-trained models, including:
- AlexNet_ImageNet_CNTK
- ResNet18_ImageNet_CNTK
- ResNet34_ImageNet_CNTK
- ResNet50_ImageNet_CNTK
- ResNet101_ImageNet_CNTK
- ResNet152_ImageNet_CNTK
- User_Defined_Model
Shape: Array of dimensions indicating the Input shape of the data used for the pre-trained model. This cannot be modified.
ResNet

In deep learning architecture, we will face the training speed and saturate accuracy problems when we increase the number of layers. Residual Neural Network architecture is introduced to allow us to increase the number of layers, yet improving accuracy and avoid the problem of vanishing gradients. ResNet node contains Residual Neural Network layers. Similar to TL Model, the dense layers can also be used after the ResNet layer to create a complete deep learning model.
The ResNet node architecture is designed to follow the ResNet paper. For more information, please visit Microsoft CNTK hand-on tutorial on the ResNet image classification.
Parameters
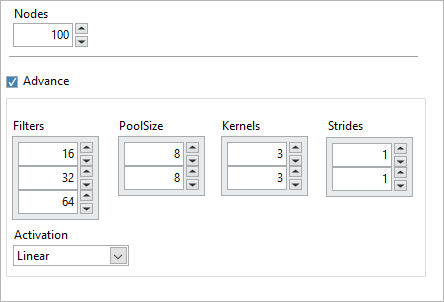
Nodes: The number of the Residual Neural Network outputs.
Activation: include
- Linear
- ReLU
- Sigmoid
- Tanh
- Softmax
- SoftPlus
- Softsign